How to scrape hidden JavaScript objects in HTML
Learn about "hidden" data found within the JavaScript of certain pages, which can increase the scraper reliability and improve your development experience.
Depending on the technology the target website is using, the data to be collected not only can be found within HTML elements, but also in a JSON format within <script> tags in the DOM.
The advantages of using these objects instead of parsing the HTML are that parsing JSON is much simpler, and more reliable than parsing HTML elements. They are much less likely to change, while the CSS selectors are prone to updates and re-namings every time the website is updated.
Note: In this tutorial, we'll be using SoundCloud's website as an example target, but the techniques described here can be applied to any site.
Locating JSON objects within script tags
Using our DevTools, we can inspect our target page, or right click the page and click View Page Source to see the DOM. Next, we'll find a value on the page that we can predict would be in a potential API response. For our page, we'll use the Tracks count of 845. On the View Page Source page, we'll do ⌘ + F and type in this value, which will show all matches for it within the DOM. This method can expose <script> tag objects which hold the target data.
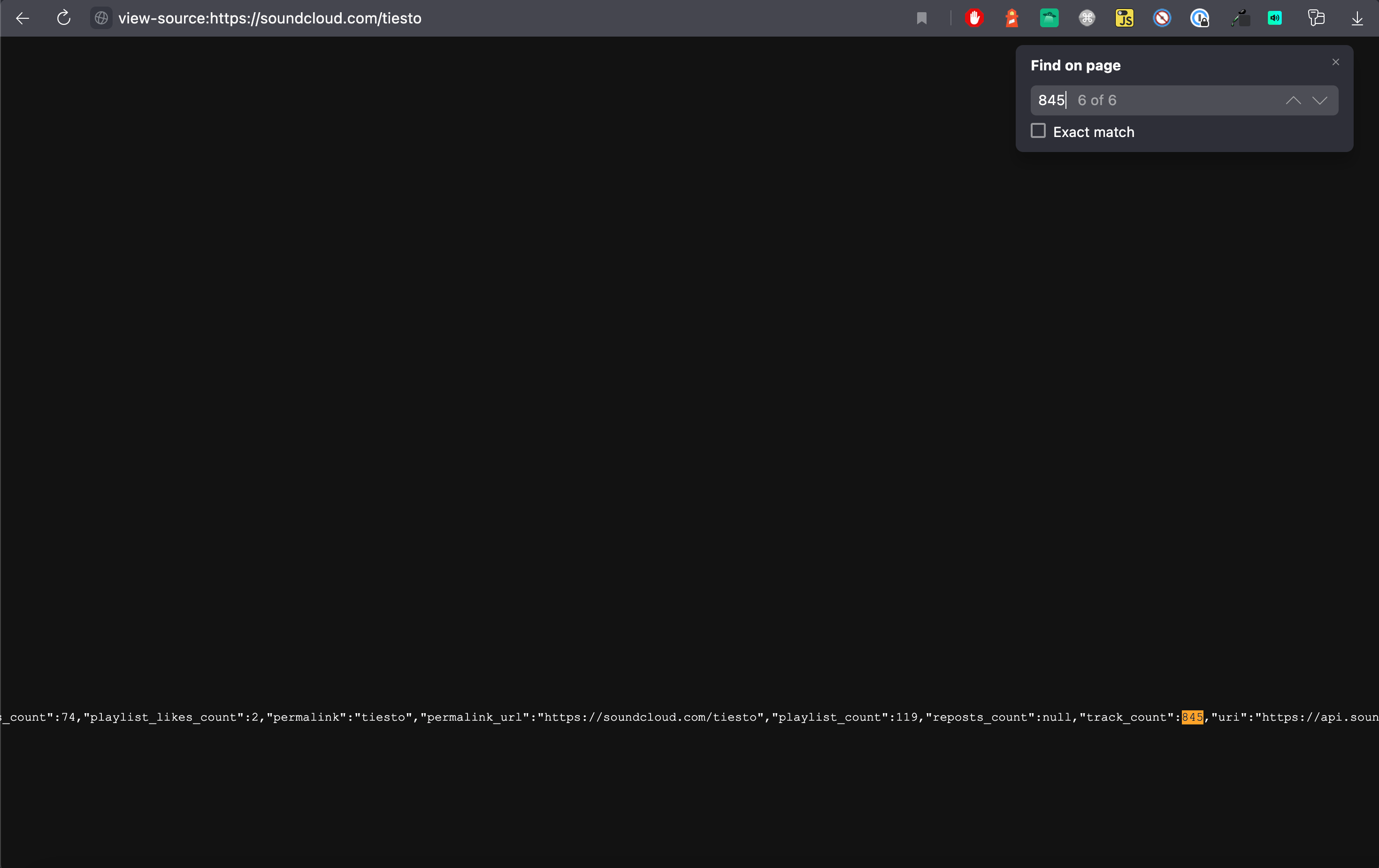
These data objects will usually be attached to the window object (often prefixed with two underscores - __). When scrolling to the beginning of the script tag on our View Page Source page, we see that the name of our target object is __sc_hydration. Heading back to DevTools and typing this into the console, the object is displayed.
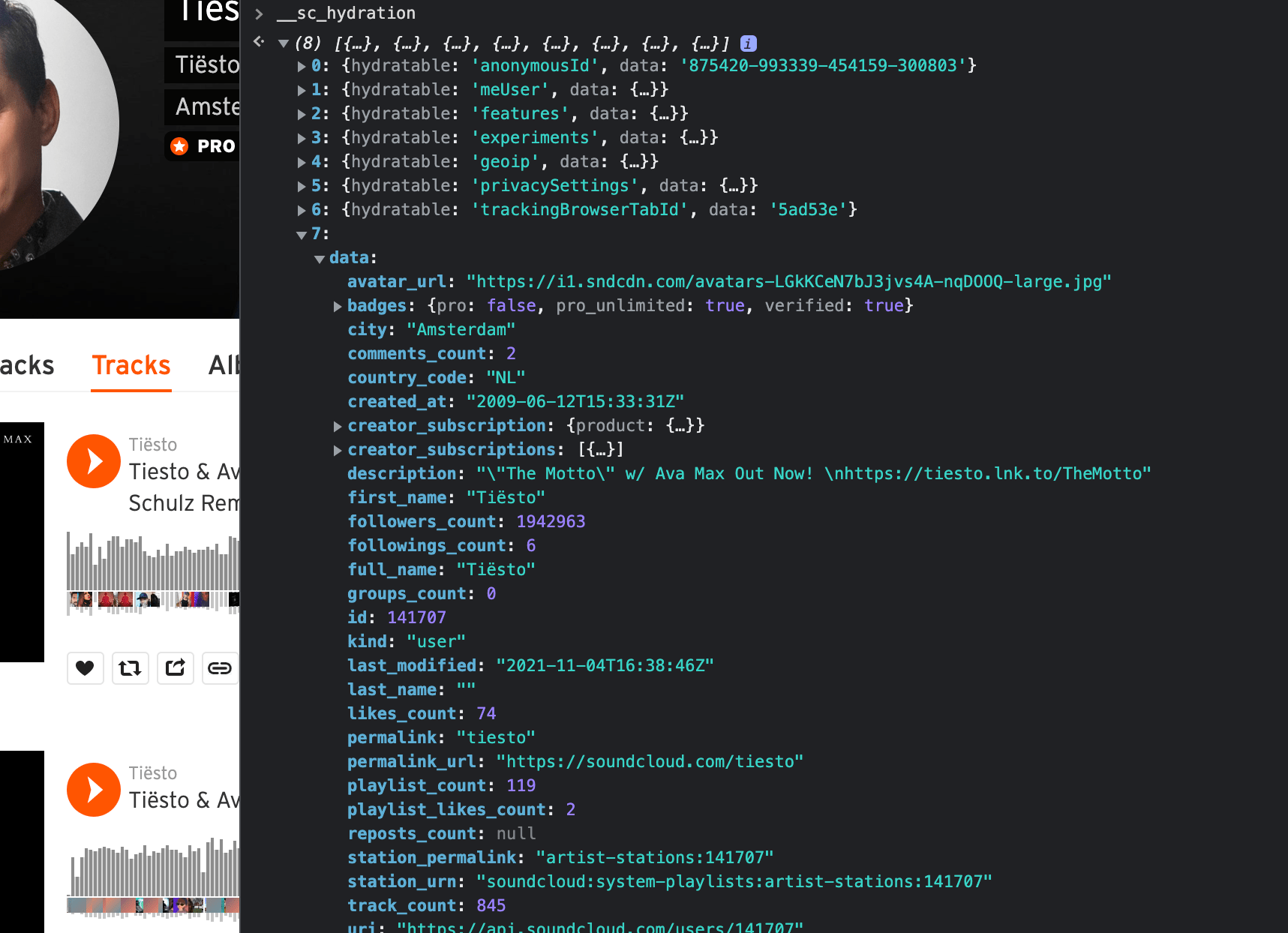
Parsing
There are two ways to go about obtaining these objects to be used and manipulated in JavaScript code:
1. Parsing them directly from the HTML
// same as "document.querySelector('html').innerHTML"
const html = $.html();
const string = html.split('window.__sc_hydration = ')[1].split(';</script>')[0];
const data = JSON.parse(string);
console.log(data);
2. Retrieving them within the context of the browser
Tools like Puppeteer allow us to run code within the context in the browser, as well as return things out of these functions and use the data back in the Node.js context.
const data = await page.evaluate(() => window.__sc_hydration);
console.log(data);
Which of these methods you use totally depends on the type of crawler you are using. Grabbing the data directly from the window object within the context of the browser using Puppeteer is of course the most reliable solution; however, it is less performant than making a static HTTP request and parsing the object directly from the downloaded HTML.